In this notebook, we will get familiar with PyTorch, a powerful machine learning framework designed for neural networks and other machine learning applications.
Learning Objectives
Describe the PyTorch package and how it leverages optimized tensor operations and GPU acceleration.
Outline the components of a neural network implemented in PyTorch.
Implement a multi-layer perceptron in PyTorch.
Import modules
Begin by importing the modules to be used in this notebook.
import os
import numpy as np
import matplotlib.pyplot as plt
import struct
import time# modules from PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDatasetWhat is PyTorch?¶
PyTorch is a machine learning framework that bundles up all of the calculus and linear algebra necessary to build and train neural networks behind the scenes, allowing the user to focus on the structure of the model. The calculations are done with PyTorch tensors which are similar to numpy arrays but designed to leverage the power of GPUs when present (although the functions also work on CPUs). When using PyTorch, we can check whether we have a GPU available on our machine and use this for calculations. Otherwise, we can just use CPUs:
if torch.cuda.is_available():
device_name = "cuda"
elif torch.backends.mps.is_available():
device_name = "mps"
else:
device_name = "cpu"
print('Using device: '+device_name)
device = torch.device(device_name)Using device: mps
With our device identified, we are ready to start some calculations. Just like with numpy, we can perform basic matrix calculations with PyTorch tensors. Let’s check on the speed of these calculations using a matrix multiplication example. Begin by defining some random numpy arrays, and then an identical tensor in PyTorch:
# define a matrix size
n = 2
# define numpy matrices
A = np.random.randn(n, n).astype(np.float32)
B = np.random.randn(n, n).astype(np.float32)
# define equivalent PyTorch tensors
A_tensor = torch.tensor(A, device=device).float()
B_tensor = torch.tensor(B, device=device).float()With these matrices in hand, we can test some simple matrix multiplication:
# numpy check
C = A @ B
print('numpy results:')
print(C)
# tensor check
C_tensor = A_tensor @ B_tensor
print('\ntorch results:')
print(C_tensor)numpy results:
[[ 1.6670609 3.2457175 ]
[-0.68559396 -1.2408398 ]]
torch results:
tensor([[ 1.6671, 3.2457],
[-0.6856, -1.2408]], device='mps:0')
The MNIST Dataset¶
In this notebook, we will again use the MNIST hand-drawn image data set as an example to test out models in PyTorch. Let’s re-create the function to read in the data here:
def read_mnist_images(data_directory, subset='train'):
if subset=='train':
prefix = 'train-'
else:
prefix = 't10k-'
with open(os.path.join(data_directory,'MNIST',prefix+'images.idx3-ubyte'), 'rb') as f:
# unpack header
_, num_images, num_rows, num_cols = struct.unpack('>IIII', f.read(16))
# read image data
image_data = f.read(num_images * num_rows * num_cols)
images = np.frombuffer(image_data, dtype=np.uint8)
images = images.reshape(num_images, num_rows, num_cols)
with open(os.path.join(data_directory,'MNIST',prefix+'labels.idx1-ubyte'), 'rb') as f:
# unpack header
_, num_labels = struct.unpack('>II', f.read(8))
# read label data
labels = np.frombuffer(f.read(), dtype=np.uint8)
return images, labelsNext, let’s read in the data and reshape into input arrays as in previous examples:
# load in the training and test images
train_images, train_labels = read_mnist_images('../data','train')
test_images, test_labels = read_mnist_images('../data','test')
# reshape as before
X_train = train_images.reshape(-1, 784) / 255.0
X_test = test_images.reshape(-1, 784) / 255.0
y_train = train_labels
y_test = test_labelsIn this implementation, we have read in our data into numpy arrays. However, if we want to leverage the power of PyTorch, we’ll need to change these arrays in PyTorch tensors. Let’s do that here:
# create PyTorch tensor versions of the MNIST data
X_train_tensor = torch.tensor(X_train).float()
X_test_tensor = torch.tensor(X_test).float()
y_train_tensor = torch.tensor(y_train).float()
y_test_tensor = torch.tensor(y_test).float()In addition, since we’re going to implement our model with a one-hot encoding, let’s leverage PyTorch’s one_hot function to make equivalent arrays for our image labels:
# create one-hot encoded training label tensors
y_train_onehot = F.one_hot(y_train_tensor.to(torch.int64),num_classes=10).float()
y_test_onehot = F.one_hot(y_test_tensor.to(torch.int64),num_classes=10).float()The Single-Layer Perceptron Revisited: A PyTorch Implementation¶
In our previous lesson, we saw an implementation of the single layer perceptron that we wrote as follows:
Let’s see how we implement this in PyTorch using a SingleLayerPerceptron class:
class SLP(nn.Module):
# define an init function with a Linear layer
def __init__(self, in_dim=784, out_dim=10):
super().__init__()
self.fc = nn.Linear(in_dim, out_dim)
# implement the forward method
def forward(self, x):
x = torch.sigmoid(self.fc(x))
return xHere, we can see that we made a subclass of the nn.Module class - a highly flexible framework for building neural networks. We can also see that we’ve created our linear layer using the nn.Linear class and we’ve called the sigmoid function, which is already provided by PyTorch - convenient! These simple calls will handle all of the matrix multiplication behind the scenes, and we just need to provide the shapes of our data.
Once we have our class, we can make our model object, just like we’ve done with our previous classes. The only difference is that we implement the model with our computational resources in mind (GPU vs CPU):
# make an slp model object here
slp = SLP().to(device)Ok, now that we have our model, how do we train it? If we take a look above, we see that we did NOT implement a backward method - that’s a little curious given that there is a lot of information for computing gradients of the loss function to optimize the weights in the last two notebooks. We’ll see why we didn’t implement this shortly. First, let’s define some important features that will be used to train our model.
The DataLoader¶
We’ll starting with the TensorDataset and the DataLoader:
# make a TensorDataset object for the training data
ds = TensorDataset(X_train_tensor, y_train_onehot)
# make a loader object for the training data
loader = DataLoader(ds, batch_size=64, shuffle=True)# make a TensorDataset object for the test data
ds_test = TensorDataset(X_test_tensor, y_test_onehot)
# make a loader object for the test data
test_loader = DataLoader(ds_test, batch_size=64, shuffle=True)These objects will allow us to efficiently train and use our model data. The DataLoader is an object that will provide subsets of our data from the dataset at a size given by batch_size. This will allow the model to be trained on mini-batches of data, rather than on the entire dataset at once.
The Loss Function¶
The definition of the loss function is key to the model training. Many of the common loss functions are are built into PyTorch (although you can also define your own loss function, if desired). Following the previous example, let’s use the mean square error loss function here:
# define a criterion as the Mean Square Error Loss Function
criterion = nn.MSELoss() The mean square error loss function is used here to follow the previous notebook. However, in practice, it should be noted that the cross entropy loss function is typically used in this application.
Regardless of which loss function is used, the loss function will take in the output of the forward model as well as the training labels provided by the DataLoader above. Then, the loss of the model computed from this function will be used by PyTorch to compute the gradients of the loss function with respect to the weights! In the previous two notebooks, we manually derived gradients and implemented backpropagation - in PyTorch, these gradients are computed automatically using autograd. This is a key functionality of PyTorch!
Updating the Weights¶
To implement the update to the weights computed with the gradients of the loss function, we need to implement a gradient descent algorithm. Let’s define that here:
# implement a gradient descent algorithm
optimizer = torch.optim.SGD(slp.parameters(), lr=0.5)In the above code block, SGD stands for Stochastic Gradient Descent and it implements the gradient descent algorithm for us (i.e. it will update the weights in our model based on the gradients of our loss function). It is called Stochastic because the gradients are not computed on the entire dataset the way we implemented them in our previous perceptron example. Instead, the gradients are computed on a random sample of the data as determined by the DataLoader. The SGD algorithm is one possible gradient decesnt algorithm but we will see more examples in future applications.
Putting it all together¶
Now that we’ve got our model, our loss function, and our gradient descent algorithm, we’re ready to train our model. Just as before, let’s run our forward, backward, and gradient descent algorithms, keeping track of the training and testing losses/accuracies as we go:
# make empty arrays to store the losses for each epoch
train_losses = []
train_accs = []
test_losses = []
test_accs = []
# loop through each epoch
for epoch in range(10):
#- Training Block --------------------------------
slp.train()
total_loss, correct, total = 0, 0, 0
# loop through mini-batches in the data loader
for x, y in loader:
x, y = x.to(device), y.to(device)
# forward
p = slp(x)
# backward
loss = criterion(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# compute the total loss
total_loss += loss.item() * x.size(0)
# predictions (argmax across 10 classes)
pred = p.argmax(dim=1)
true = y.argmax(dim=1)
correct += (pred == true).sum().item()
total += x.size(0)
train_loss = total_loss/total
train_acc = correct/total
train_losses.append(train_loss)
train_accs.append(train_acc)
print(f"epoch {epoch+1}: loss={total_loss/total:.4f}, acc={correct/total:.3f}")
# ---- Testing Block ----
slp.eval()
total_loss, correct, total = 0, 0, 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
p = slp(x)
loss = criterion(p, y)
batch_size = x.size(0)
total_loss += loss.item() * x.size(0)
pred = p.argmax(dim=1)
true = y.argmax(dim=1)
correct += (pred == true).sum().item()
total += x.size(0)
test_loss = total_loss/total
test_acc = correct/total
test_losses.append(test_loss)
test_accs.append(test_acc)epoch 1: loss=0.0442, acc=0.803
epoch 2: loss=0.0283, acc=0.871
epoch 3: loss=0.0252, acc=0.881
epoch 4: loss=0.0236, acc=0.887
epoch 5: loss=0.0226, acc=0.891
epoch 6: loss=0.0218, acc=0.893
epoch 7: loss=0.0212, acc=0.895
epoch 8: loss=0.0207, acc=0.897
epoch 9: loss=0.0204, acc=0.898
epoch 10: loss=0.0200, acc=0.900
Note that the .backward() call above computes the same gradients we derived in the previous notebooks.
The model appears to be performing reasonably well based on the reported losses. Let’s have a look at the losses for the training and testing sets:
# plot the losses and accuracies
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.plot(train_losses,label='Train')
plt.plot(test_losses,label='Test')
plt.ylabel('Loss')
plt.xlabel('Iterations')
plt.legend()
plt.subplot(1,2,2)
plt.plot(train_accs,label='Train')
plt.plot(test_accs,label='Test')
plt.legend()
plt.ylabel('Accuracy')
plt.ylim([0,1])
plt.xlabel('Iterations')
plt.show()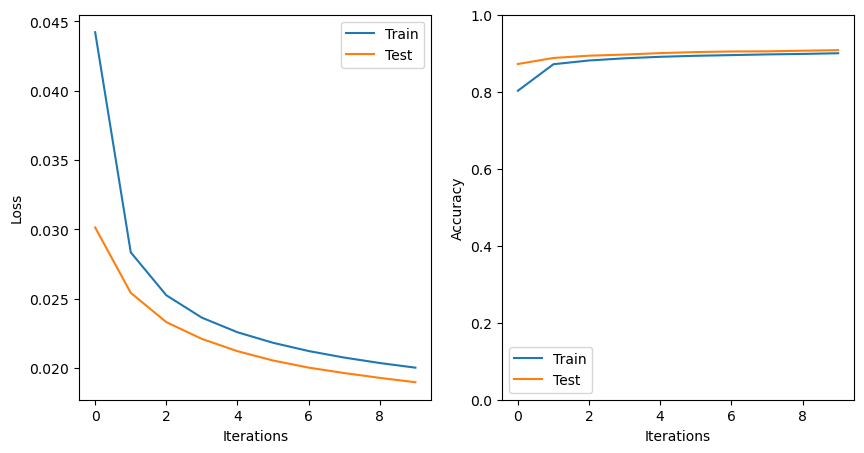
Let’s see how our model does with the classification of our images
# choose some indices of the images to test
np.random.seed(37)
test_indices = np.random.randint(low=0, high=10000, size=10)
plt.figure(figsize=(10,6))
for d, index in enumerate(test_indices):
# convert the image corresponding to this index to a tensor and predict
# the label with the model
input_tensor = X_train_tensor[index].unsqueeze(0).to(device)
predicted_label = int(slp(input_tensor).argmax(dim=1)[0])
# show the image with the predicted label
plt.subplot(2,5,d+1)
plt.imshow(train_images[index,:,:],cmap='Greys')
plt.title('True Label: '+str(train_labels[index])+\
'\n Predicted Label: '+str(predicted_label))
plt.axis('off')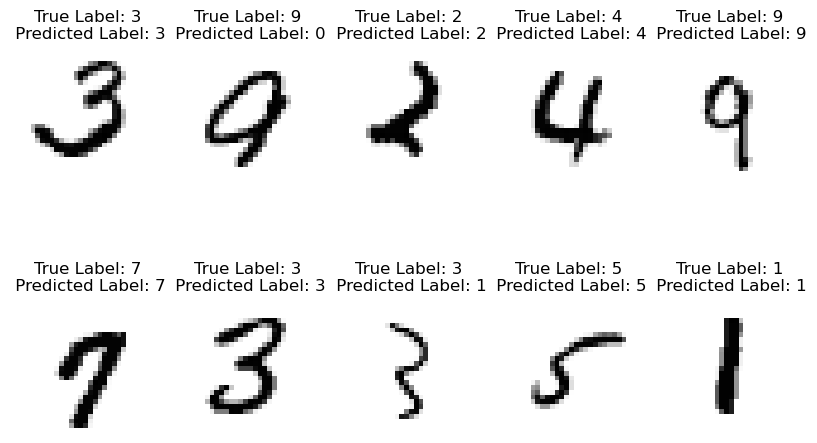
From Single- to Multi-Layer Perceptrons¶
After implementing our single layer perceptron, we added a new layer to make our multilayer perceptron. We wrote this in equations as follows:
Following the structure above, we can implement a MLP class here. We only need a few small additions to the SLP class above:
class MLP(nn.Module):
# define an init function with Linear layers
def __init__(self, in_dim=784, hidden_dim=50, out_dim=10):
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, out_dim)
# implement the forward method
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
return xNext, create an object with the MLPL class:
mlp = MLP().to(device)Then, define a loss function and a gradient descent algorithm for your model:
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(mlp.parameters(), lr=0.5)Now, your model is ready to train! Implement a training loop here:
# make empty arrays to store the losses for each epoch
train_losses = []
train_accs = []
test_losses = []
test_accs = []
# loop through each epoch
for epoch in range(10):
#- Training Block --------------------------------
mlp.train()
total_loss, correct, total = 0, 0, 0
# loop through mini-batches in the data loader
for x, y in loader:
x, y = x.to(device), y.to(device)
# forward
p = mlp(x)
# backward
loss = criterion(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# compute the total loss
total_loss += loss.item() * x.size(0)
# predictions (argmax across 10 classes)
pred = p.argmax(dim=1)
true = y.argmax(dim=1)
correct += (pred == true).sum().item()
total += x.size(0)
train_loss = total_loss/total
train_acc = correct/total
train_losses.append(train_loss)
train_accs.append(train_acc)
print(f"epoch {epoch+1}: loss={total_loss/total:.4f}, acc={correct/total:.3f}")
# ---- Testing Block ------------------
mlp.eval()
total_loss, correct, total = 0, 0, 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
p = mlp(x)
loss = criterion(p, y)
batch_size = x.size(0)
total_loss += loss.item() * x.size(0)
pred = p.argmax(dim=1)
true = y.argmax(dim=1)
correct += (pred == true).sum().item()
total += x.size(0)
test_loss = total_loss/total
test_acc = correct/total
test_losses.append(test_loss)
test_accs.append(test_acc)epoch 1: loss=0.0882, acc=0.247
epoch 2: loss=0.0686, acc=0.573
epoch 3: loss=0.0480, acc=0.762
epoch 4: loss=0.0369, acc=0.832
epoch 5: loss=0.0306, acc=0.859
epoch 6: loss=0.0267, acc=0.873
epoch 7: loss=0.0241, acc=0.882
epoch 8: loss=0.0222, acc=0.888
epoch 9: loss=0.0208, acc=0.893
epoch 10: loss=0.0198, acc=0.896
# plot the losses and accuracies
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.plot(train_losses,label='Train')
plt.plot(test_losses,label='Test')
plt.ylabel('Loss')
plt.xlabel('Iterations')
plt.legend()
plt.subplot(1,2,2)
plt.plot(train_accs,label='Train')
plt.plot(test_accs,label='Test')
plt.legend()
plt.ylabel('Accuracy')
plt.ylim([0,1])
plt.xlabel('Iterations')
plt.show()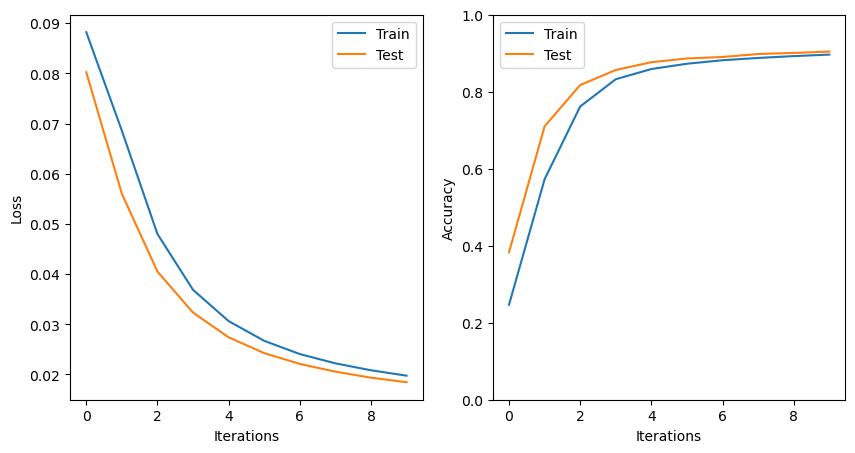
Compare and contrast the single and multi-layer models created above. Which model performs better on the test set, and why?
Key Takeaways
PyTorch uses tensor objects for efficient computations.
PyTorch provides a convenient approach to generate neural network models without having to explicitly code up tedious details for loss functions, backpropagation, or gradient descent.
A PyTorch
nn.Moduleclass is a flexible framework for various model structures.
- Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Köpf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., … Chintala, S. (2019). PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv. 10.48550/ARXIV.1912.01703