In this notebook, we will expand on our implementation of the single-layer perceptron to create a multi-layer perceptron. This implementation will allow our model to learn more complex structures in hand-drawn numbers compared to the single-layer implementation.
Learning Objectives
Implement a multi-layer perceptron for multi-class classification of multidimensional data.
Compute the gradient of a multi-dimensional loss function for use in a multi-layer perceptron.
Implement a multi-layer perceptron in a Python class.
Import modules
Begin by importing the modules to be used in this notebook.
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import structThe MNIST Dataset¶
In this notebook, we will expand on the single layer perceptron introduced in the previous notebook. We will use the same data - the MNIST hand-drawn image dataset. Here, let’s re-implement the function to read in the MNIST images.
def read_mnist_images(data_directory, subset='train'):
if subset=='train':
prefix = 'train-'
else:
prefix = 't10k-'
with open(os.path.join(data_directory,'MNIST',prefix+'images.idx3-ubyte'), 'rb') as f:
# unpack header
_, num_images, num_rows, num_cols = struct.unpack('>IIII', f.read(16))
# read image data
image_data = f.read(num_images * num_rows * num_cols)
images = np.frombuffer(image_data, dtype=np.uint8)
images = images.reshape(num_images, num_rows, num_cols)
with open(os.path.join(data_directory,'MNIST',prefix+'labels.idx1-ubyte'), 'rb') as f:
# unpack header
_, num_labels = struct.unpack('>II', f.read(8))
# read label data
labels = np.frombuffer(f.read(), dtype=np.uint8)
return images, labelsSimilarly, let’s read in our images and reshape them into a stack of “unraveled” images.
# load in the training and test images
train_images, train_labels = read_mnist_images('../data','train')
test_images, test_labels = read_mnist_images('../data','test')
# reshape as before
X_train = train_images.reshape(-1, 784) / 255.0
X_test = test_images.reshape(-1, 784) / 255.0
Y_train = train_labels
Y_test = test_labelsThe Multi-Layer Perceptron¶
In our previous implementation, each class probability was computed directly from the raw pixel values through a single linear transformation. For example, if an image had dark pixels in a vertical line near the center of the image but nowhere else, then that image would yield a high probability for class 1. If there were some additional pixels in the upper left-hand corner of the image, perhaps that would be an elevated probability that the image was a 7. However, sometimes we need to make more complex decisions to account for variations in handwriting. For example, some people write their 4’s with a connected tip at the top, and some people keep theirs open. Check out the following example for comparison:
fig = plt.figure(figsize=(5,2))
plt.subplot(1,2,1)
plt.imshow(train_images[58,:,:], cmap='Greys')
plt.title('Open 4')
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(train_images[150,:,:], cmap='Greys')
plt.title('Closed 4')
plt.axis('off')
plt.show()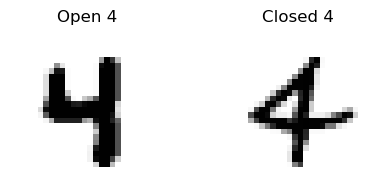
Clearly, we want our algorithm to work for both of these examples, but these are considerably different shapes. So how can we implement an algorithm to make a choice like this?
Implementing Hidden Layers¶
To implement non-linear decisions into a neural network, we can build in hidden layers into our model. A hidden layer is simply a layer which is not an input layer and also not an output layer - it’s an intermediate layer that is the result of a linear combination of weights and an activation function that is then passed on to another linear combination of weights.
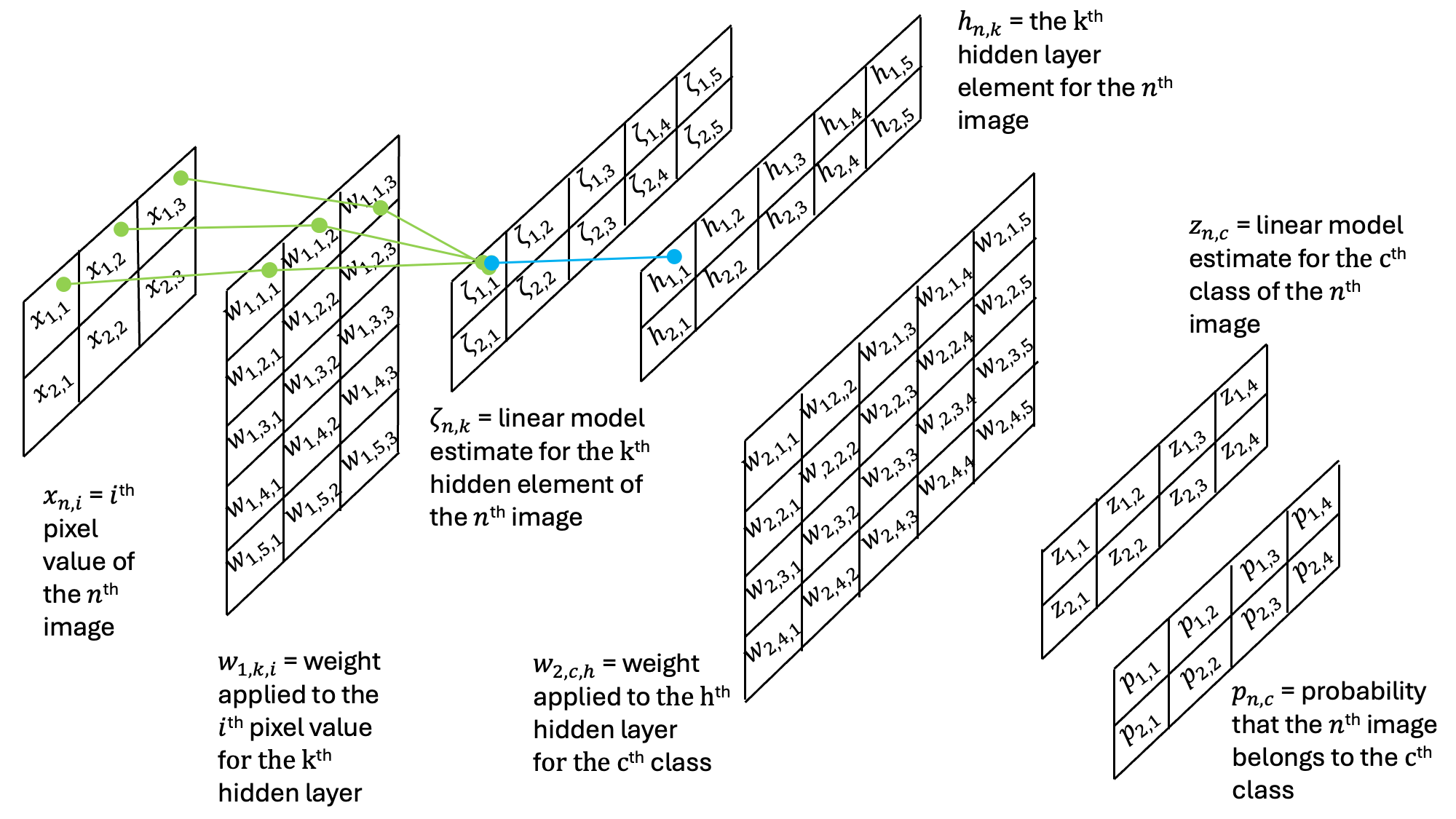
To see how these layers work, let’s build in a hidden layer to our multi-layer perceptron. In this model, we will have an initial layer of weights and a bias vector that linearly combine to produce . Then, is passed through an activation function to give the values in the hidden layer . Subsequently, is passed through a network which is nearly identical to the single-layer perceptron from our previous example.
To provide a concrete example for the shapes of all matrices in this network, we can step through a miniature example with matrices that have the following sizes:
X: (2, 3)
: (5, 3)
: (2, 5)
: (2, 5)
: (4, 5)
z: (2, 4)
p: (2, 4)
In the first step, we can see how the weights combine to yield the contents of the hidden layer:
Then, this result is then passed through an additional set of weights and an additional activation function:
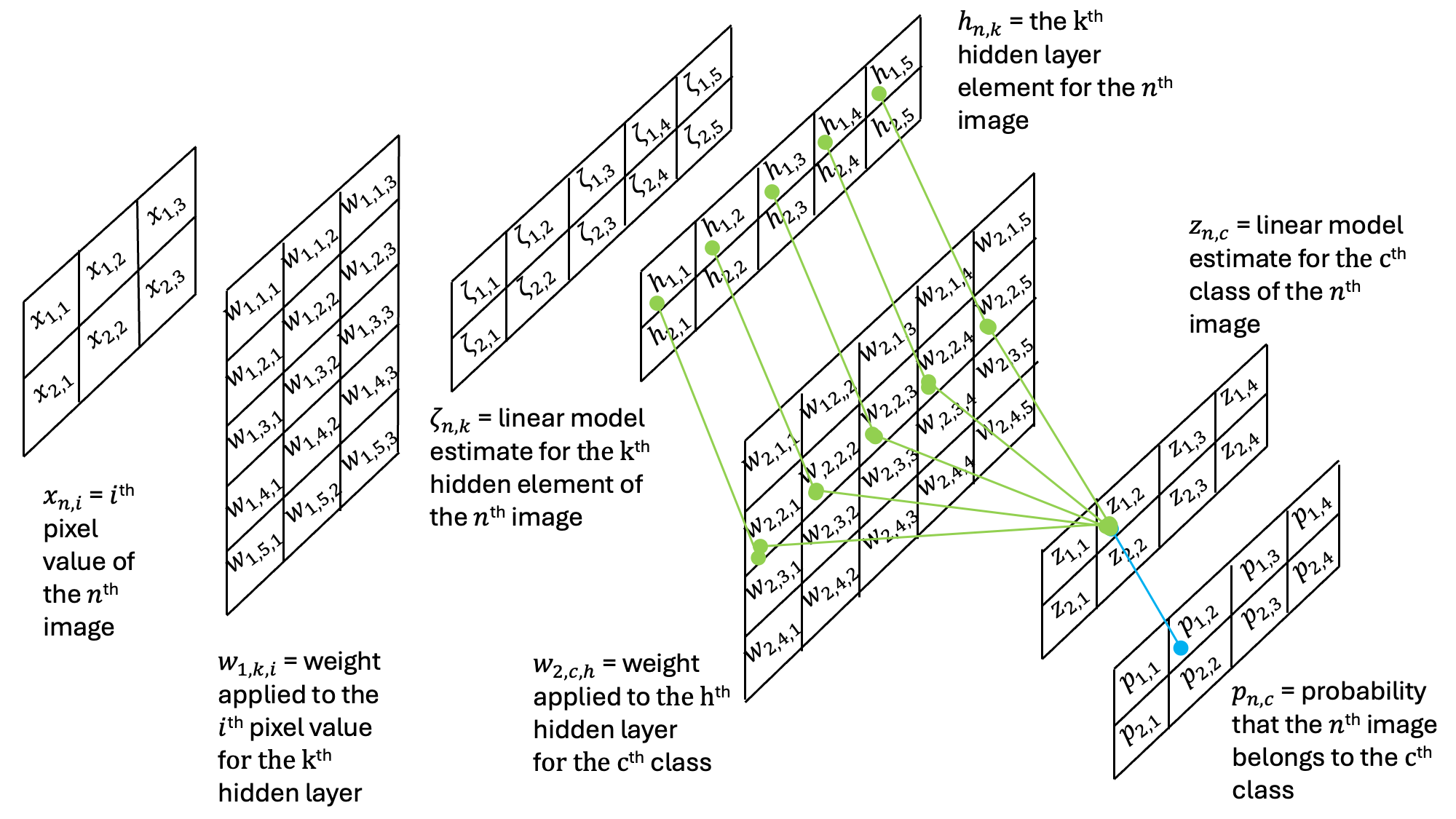
Note that the output probabilities are the same shape as the output probabilities in the previous single-layer perceptron example.
The Loss Function¶
To compute the optimal weights for our model, we’ll need to define a loss function. Here, we will again use the mean square error loss function:
Here, the loss is computed across all of the images (60,000 in this case) and all of the classes (10 in this case).
The Derivative of the Loss Function¶
To use the gradient descent algorithm for each of our weights, we need to compute the derivatives of the loss function with respect to each of the weights in each of the weight matrices connecting the layers of our model. Here, we’ll start by discussing the second weight matrix and then we’ll address the first. The reason for this ordering will become apparent shortly.
The Second Weight Matrix¶
While we implement our model from the input images through to the output probabilities, we are first going to consider the derivatives of the loss function with respect to the second set of weights, .
If we examine the second schematic figure above, we find that this is identical to the single layer perceptron. Thus, the gradients are identical and are solved by the chain rule yielding:
This is almost identical to the derivative of the loss function with respect to the weights in the single-layer perceptron example (see HERE). However, some notes are helpful for our understanding. First, there is a subscript of 2 on signifying these are weights of the second linear model. Second, we see that has replaced as the second layer output uses output from the first. Other than these details, all of the calculations of the derivatives are the same because the numerical structure of the connections between the hidden layer and output layer are identical to the single-layer perceptron. Just as before, we may again concisely write:
where
The First Weight Matrix¶
Now that we’ve computed the second weight matrix, we can move on to the first. Now, consider the second diagram above and consider the weight .
As we can see, the loss function’s dependence on weight is a function of all the weights that connected the output layer to the first element of the hidden layer. Thus, when computing the derivative, we need to consider all of the different probability values - not just those which correspond to an individual column. Let’s write out the full derivative for the weight above:
Here, we can start filling in the different derivates. First, the first two terms are just given by (an important observation since we have already computed this!). The next two terms are also easy because this is the derivative of the sigmoid activation function, which we’ve already computed. Finally, the last term is just the derivative of a function with a constant slope. Substituting these expressions into the derivative above yields:
Here again, we can define a formula to make the multiplication more concise:
With this in hand, the full loss gradient can be defined as follows:
As before, we can express this as the multiplication of matrices:
This gives us a recipe to compute the loss gradients - but we also need to compute . Looking back to the definition above, we can see that this can be accomplished with the following computation:
where I have used the operator here to indicate element-wise multiplication (rather than matrix multiplication, which is assumed when two matrices are put next to each other). It is key to note here that all of the terms (, , and ) are already computed in either the calculation for or the forward pass.
Algorithmic Summary¶
Ok, that’s a lot of details, let’s do a quick review before we code it up.
Forward Model Algorithm¶
To compute the forward model, there are two steps: $$
$$
Not too bad... right?
Backward Model Algorithm¶
In the backward model, we compute the gradients of the loss functions with respect to the weight matrices. First, we need to compute the gradient of the loss function with respect to the second set of weights. We can do this short-hand by computing as
Note that we computed and in the forward step so this information is at hand! Using this matrix, we get the losses as
We did not show it here, but we can also get the gradient of the loss function with respect to the second bias matrix as
Next up, we compute the gradient of the loss function with respect to the first set of weights. Again, we can do this compactly by computing as $$
$$
Using this matrix, we get the losses as
Again, we can also get the gradient of the loss function with respect to the first bias matrix as
Coding Up a Solution¶
Now that we know how to compute our gradients, let’s write some code to create our model!
class MultiLayerPerceptron:
def __init__(self, num_features, num_hidden, num_classes, random_seed=123):
self.num_classes = num_classes
rng = np.random.RandomState(random_seed)
# first layer weights and biases
self.weight_h = rng.normal(loc=0.0, scale=0.1, size=(num_hidden, num_features))
self.bias_h = np.zeros(num_hidden)
# second layer weights and biases
self.weight_out = rng.normal(loc=0.0, scale=0.1, size=(num_classes, num_hidden))
self.bias_out = np.zeros(num_classes)
def int_to_onehot(self, y, num_labels):
ary = np.zeros((y.shape[0], num_labels))
for i, val in enumerate(y):
ary[i, val] = 1
return(ary)
def sigmoid(self,z):
return 1 / (1 + np.exp(-np.clip(z, -250, 250))) # clipping prevent overflows
def forward(self, x):
zeta = np.dot(x, self.weight_h.T) + self.bias_h
h = self.sigmoid(zeta)
z = np.dot(h, self.weight_out.T) + self.bias_out
p = self.sigmoid(z)
return(h, p)
def predict(self, X):
_, probs = self.forward(X)
return np.argmax(probs, axis=1)
def backward(self, x, h, p, y):
# encode the labels with one-hot encoding
y_onehot = self.int_to_onehot(y, self.num_classes)
# Part 1: dLoss/dw2
D2 = -2*(y_onehot-p)/y.shape[0] * p*(1-p)
d_L__d_w2 = np.dot(D2.T, h)
d_L__d_b2 = np.dot(D2.T, np.ones_like(y))
# Part 2: dLoss/dw1
D1 = np.dot(D2, self.weight_out) * h * (1-h)
d_L__d_w1 = np.dot(D1.T, x)
d_L__d_b1 = np.dot(D1.T, np.ones_like(y))
return(d_L__d_w2, d_L__d_b2,
d_L__d_w1, d_L__d_b1)
def mse_loss(self, targets, probs, num_labels=10):
onehot_targets = self.int_to_onehot(targets, num_labels)
err = np.mean((onehot_targets - probs)**2)
return(err)
def compute_mse_and_acc(self, X, y, num_labels=10):
_, probs = self.forward(X)
predicted_labels = np.argmax(probs,axis=1)
onehot_targets = self.int_to_onehot(y, num_labels)
loss = np.mean((onehot_targets - probs)**2)
acc = np.sum(predicted_labels == y)/len(y)
return(loss, acc)
def train(self,X_train, Y_train, X_test, Y_test, num_epochs, learning_rate=0.1):
train_losses = []
test_losses = []
train_accs = []
test_accs = []
for e in range(num_epochs):
# compute the forward method
h, p = self.forward(X_train)
# compute the backward method
d_L__d_w2, d_L__d_b2, \
d_L__d_w1, d_L__d_b1 = self.backward(X_train, h, p, Y_train)
# gradient descent
self.weight_out -= learning_rate*d_L__d_w2
self.bias_out -= learning_rate*d_L__d_b2
self.weight_h -= learning_rate*d_L__d_w1
self.bias_h -= learning_rate*d_L__d_b1
# keep track of stats
train_loss, train_acc = self.compute_mse_and_acc(X_train, Y_train)
train_losses.append(train_loss)
train_accs.append(train_acc)
test_loss, test_acc = self.compute_mse_and_acc(X_test, Y_test)
test_losses.append(test_loss)
test_accs.append(test_acc)
return(train_losses, train_accs, test_losses, test_accs)Let’s give it a spin!
mlp = MultiLayerPerceptron(784,50,10)
train_losses, train_accs, test_losses, test_accs = \
mlp.train(X_train, Y_train, X_test, Y_test, 1000, learning_rate=0.5)Now that we’ve trained the model, let’s take a look at our loss function and accuracies:
# plot the losses and accuracies
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.plot(train_losses,label='Train')
plt.plot(test_losses,label='Test')
plt.ylabel('Loss')
plt.xlabel('Iterations')
plt.legend()
plt.subplot(1,2,2)
plt.plot(train_accs,label='Train')
plt.plot(test_accs,label='Test')
plt.ylabel('Accuracy')
plt.ylim([0,1])
plt.xlabel('Iterations')
plt.show()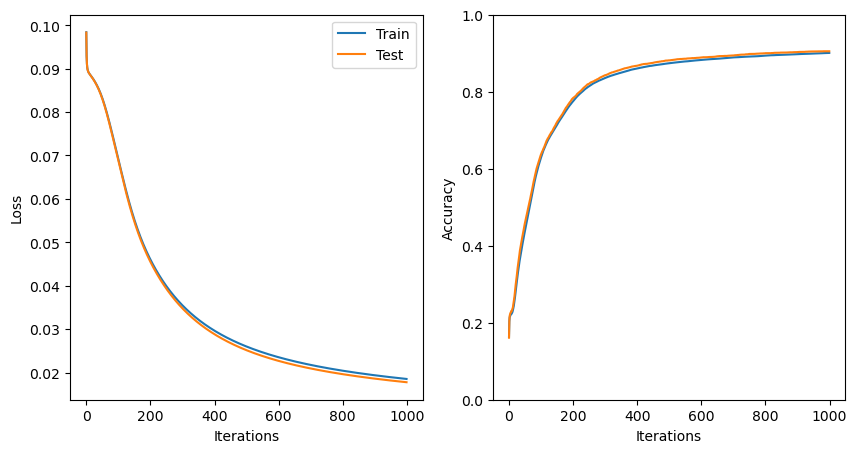
Just as for the single-layer perceptron, with more than 1000 iterations and a learning rate of 0.5, our model has now started to converge.
Let’s see how it works on a collection of random images:
np.random.seed(37)
test_indices = np.random.randint(low=0, high=10000, size=10)
plt.figure(figsize=(10,6))
for d, index in enumerate(test_indices):
plt.subplot(2,5,d+1)
plt.imshow(train_images[index,:,:],cmap='Greys')
plt.title('True Label: '+str(train_labels[index])+\
'\n Predicted Label: '+str(mlp.predict(train_images[index,:,:].reshape(1, 784))[0]))
plt.axis('off')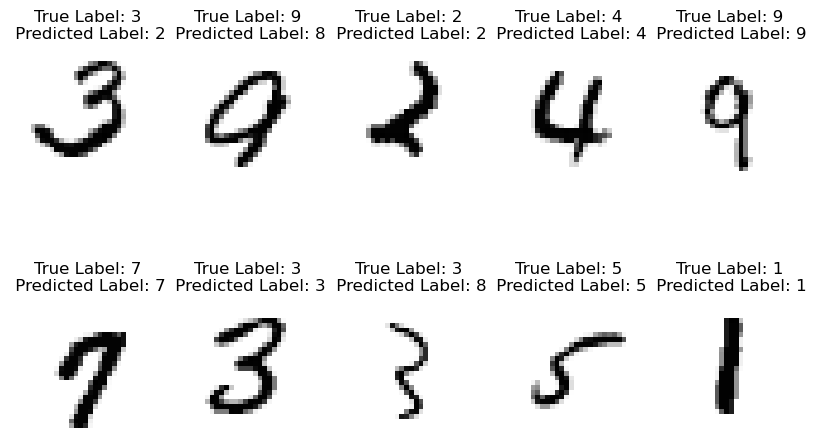
Seems like we’re doing pretty good! Be sure to compare these results to the single-layer perceptron.
Key Takeaways
A hidden layer provides a mechanism for models to make non-linear decisions.
Implementing a hidden layer into a network introduces one additional matrix stored in memory as well as two additional matrix operations.
Hidden layers can substantially improve the ability of a model to learn complex features in a data set.